import matplotlib.pyplot as plt
# ---------- Dados ----------
marcos = [
(1956, "Dartmouth Workshop\n(nascimento da IA)"),
(1986, "Backpropagation\n(popularização)"),
(1997, "Deep Blue\n(derrota Kasparov)"),
(2012, "AlexNet\n(revolução em visão)"),
(2017, "Attention is All You Need\n(Transformer)"),
(2018, "BERT\n(encoder bidirecional)"),
(2020, "GPT-3\n(175B parâmetros)"),
(2022, "ChatGPT\n(popularização dos LLMs)"),
(2023, "GPT-4\n(multimodal inicial)"),
(2023, "LLaMA 1 (Meta)\n(ecossistema aberto)"),
(2023, "Gemini 1 (Google DeepMind)\n(multimodal)"),
(2023, "Mistral 7B\n(eficiência)"),
(2024, "Claude 3\n(alinhamento e contexto)"),
(2024, "LLaMA 3 (Meta)\n(ecossistema aberto)"),
(2024, "Mixtral 8x7B (Mistral)\n(Mixture of Experts)"),
(2024, "Gemini 1.5\n(janelas longas)"),
(2025, "Modelos multimodais e agentes de IA\n(nova etapa de integração)"),
]
gap = 3.2
anos = [i * gap for i in range(len(marcos))]
labels = [f"{ano} — {texto}" for ano, texto in marcos]
fig, ax = plt.subplots(figsize=(6.4, 11), dpi=150)
ax.vlines(1, min(anos) - gap, max(anos) + gap, linewidth=2)
ax.plot([1] * len(anos), anos, "o", markersize=7, color="black")
for i, (y, text) in enumerate(zip(anos, labels)):
is_left = (i % 2 == 0)
x_text = 0.84 if is_left else 1.16
ha = "right" if is_left else "left"
ax.annotate(
text,
xy=(1, y),
xytext=(x_text, y),
textcoords="data",
va="center",
ha=ha,
fontsize=9,
arrowprops=dict(arrowstyle="-", lw=0.7, alpha=0.8),
bbox=dict(boxstyle="round,pad=0.25", alpha=0.85),
)
ax.set_xlim(0.7, 1.3)
ax.set_xticks([])
ax.set_yticks([])
ax.set_title(
"Linha do Tempo — Evolução da Inteligência Artificial",
fontsize=11.5,
weight="bold",
pad=12,
)
ax.set_ylabel("")
plt.tight_layout()
plt.savefig("images/ia-timeline-vertical.png", bbox_inches="tight")
plt.close()🧠 Inteligência Artificial — Índice da Seção
inteligência artificial
IA
LLM
história da computação
aprendizado de máquina
deep learning
programação
ética
atenção
aplicações
Página inicial da seção de IA do Blog do Marcellini: história da inteligência artificial, linha do tempo, série sobre LLMs e próximos conteúdos.
🧠 Inteligência Artificial
A Inteligência Artificial é uma das áreas mais influentes da computação contemporânea. Ela reúne ideias vindas da matemática, da lógica, da estatística, da ciência da computação, da neurociência, da filosofia e da engenharia.
Nesta seção do Blog do Marcellini, a IA é apresentada em duas frentes complementares:
- uma frente histórica, que acompanha a evolução das ideias, promessas, crises e renascimentos da área;
- uma frente técnica e conceitual, dedicada aos Large Language Models (LLMs), aos Transformers, ao mecanismo de atenção e às aplicações modernas da IA generativa.
🧭 Linha do tempo da IA
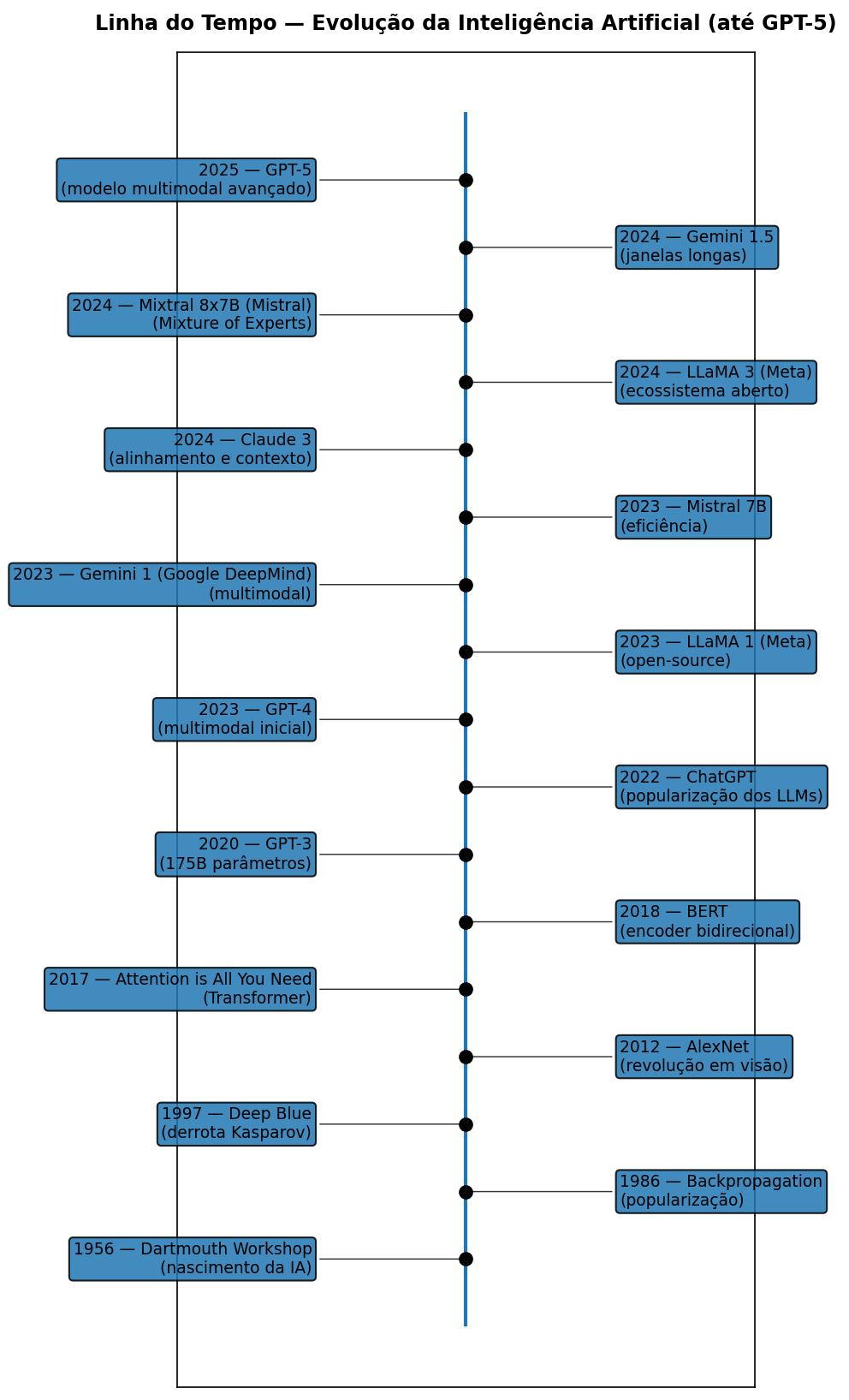
ImportanteCódigo em Python (clique para expandir) — gera a linha do tempo acima
📚 Série 1 — História da Inteligência Artificial
A série História da Inteligência Artificial acompanha a trajetória da IA desde seus antecedentes filosóficos e lógicos até os modelos generativos contemporâneos.
Ela foi pensada como uma porta de entrada para entender que a IA não surgiu de repente: antes dos chatbots e dos modelos de linguagem, houve autômatos, lógica simbólica, cibernética, sistemas especialistas, redes neurais, invernos de financiamento, renascimentos estatísticos e novas arquiteturas computacionais.
📖 Posts da série
- Origens e Sonhos
- Nascimento da IA
- Os Anos Dourados
- O Inverno da IA
- O Renascimento da IA
- A Era dos Modelos Generativos
- O Futuro da IA
👉 Acesse o índice da série História da IA
💬 Série 2 — Large Language Models (LLMs)
Os Large Language Models (LLMs) estão no centro da IA generativa moderna. Eles conseguem gerar texto, escrever código, resumir documentos, responder perguntas, auxiliar no estudo e transformar fluxos de trabalho em diversas áreas.
Nesta série, estudamos:
- o que são LLMs;
- como a arquitetura Transformer mudou o processamento de linguagem natural;
- como funciona o mecanismo de atenção;
- como ocorre o treinamento com pré-treinamento, fine-tuning e RLHF;
- quais são as limitações, riscos e aplicações práticas desses modelos.
📖 Posts da série
- O que é um Large Language Model (LLM)?
- Atenção em Transformers: Q, K, V e Multi-Head Attention
- Como os LLMs são treinados: Pré-treinamento, Fine-Tuning e RLHF
- Desafios e Limitações dos LLMs
- Aplicações Práticas dos LLMs
- O Futuro dos LLMs e da IA Generativa