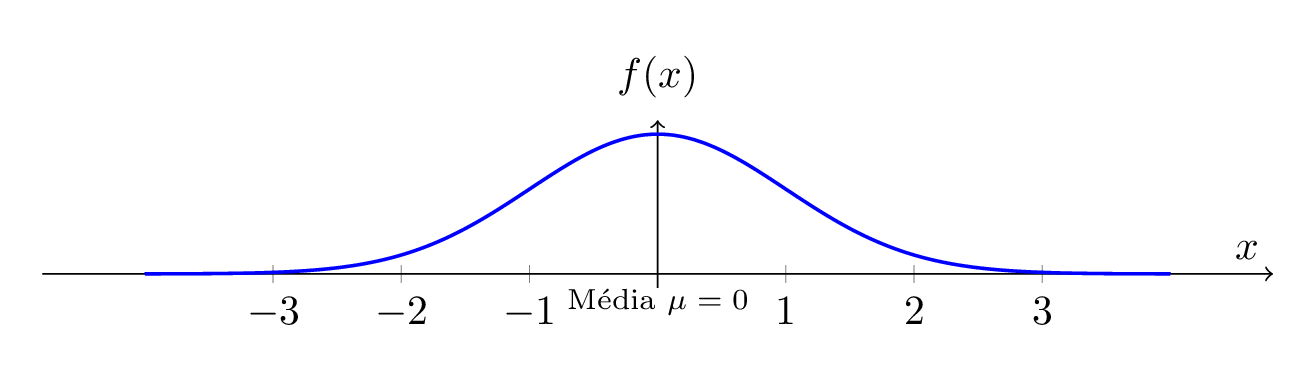🎓 📊 A Distribuição Normal — Parte 1
Este curso tem como propósito apresentar, de forma acessível e aplicada, os fundamentos da distribuição normal, também conhecida como distribuição de Gauss, com apoio de visualizações gráficas e ferramentas computacionais.
- A curva de Gauss e a Regra Empírica;
- O conceito de escore-\(z\) e como usá-lo para calcular probabilidades;
- A interpretação da área sob a curva e suas aplicações em situações reais;
- Cálculos práticos com o uso da Tabela Z, R e Excel.
Antes de mergulhar na distribuição normal, é fundamental compreender alguns conceitos-chave da estatística. Eles fornecem a base para entender como podemos descrever e analisar dados no mundo real.
🔢 População
É o conjunto completo de elementos com uma característica de interesse.
Exemplos: todos os alunos de uma escola, todas as lâmpadas produzidas por uma fábrica, ou todos os habitantes de um país.
🧪 Amostra
É um subconjunto da população, usado quando é inviável medir todos os elementos. Uma amostra bem escolhida permite fazer inferências sobre a população.
Exemplo: medir o QI de 200 estudantes para estimar o QI médio da escola.
-
🎲 Variável aleatória
Representa um fenômeno incerto, cujos valores possíveis são associados a resultados numéricos.
Pode ser:
-
Discreta: assume valores específicos e contáveis (número de filhos por família, chamadas atendidas por dia).
-
Contínua: assume qualquer valor dentro de um intervalo (altura, tempo, temperatura, QI).
📊 Distribuição de probabilidade
Mostra como os valores de uma variável aleatória estão distribuídos.
Exemplos: a chance de um bebê nascer com determinado peso; a probabilidade de um carro consumir certa quantidade de combustível.
📈 Função densidade de probabilidade (FDP)
Para variáveis contínuas, usamos curvas em vez de tabelas. A altura da curva indica a probabilidade relativa de cada valor, e a área sob a curva representa a probabilidade total de um intervalo.
Exemplo: a área entre 160 cm e 170 cm na curva da altura humana indica a proporção de pessoas nessa faixa.
⚖️ Média (\(\mu\))
Valor central da distribuição.
Exemplo: se a média de estatura dos adultos é 170 cm, então esse é o ponto de equilíbrio da curva.
📐 Desvio padrão (\(\sigma\))
Mede a dispersão dos dados em torno da média. Quanto maior \(\sigma\), mais “espalhados” estão os dados.
Exemplo: se a média de QI é 100 e \(\sigma = 15\), a maioria das pessoas terá QI entre 85 e 115.
A distribuição normal é um modelo estatístico essencial porque descreve com precisão muitos fenômenos do mundo real — tanto naturais quanto sociais. Ela surge, sobretudo, quando várias causas aleatórias e independentes influenciam um resultado final. Nessas situações, os dados tendem a se concentrar em torno de uma média, formando a clássica curva em forma de sino.
🔎 Por que isso importa?
Porque a normalidade simplifica a análise estatística e viabiliza o uso de ferramentas poderosas de inferência.
📌 Exemplos práticos:
📚 Notas em provas padronizadas: os escores se distribuem em torno da média, com poucos alunos obtendo notas muito altas ou muito baixas.
🌿 Altura de plantas de uma mesma espécie cultivadas sob condições semelhantes tende a se agrupar em torno de um valor central.
📉 Retornos de ativos financeiros (ações, moedas) se aproximam de uma curva normal em períodos curtos — embora com ressalvas quanto a eventos extremos.
📈 Com a suposição de normalidade, podemos:
Calcular probabilidades com fórmulas e tabelas conhecidas;
Estimar intervalos de confiança;
Aplicar testes de hipóteses;
Visualizar dados de forma clara e comparável.
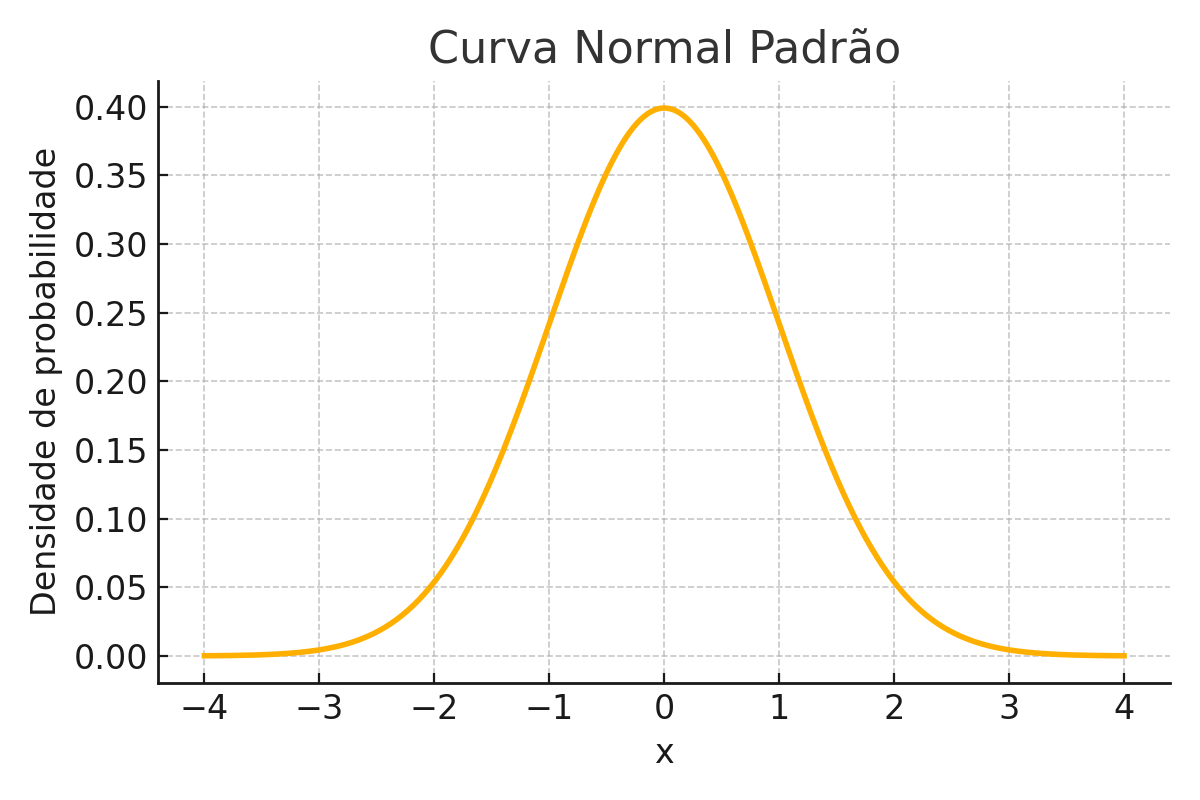
📏 Curva Normal Padrão
A curva normal, também conhecida como distribuição de Gauss, é uma das ferramentas mais fundamentais da estatística. Ela descreve como certas variáveis se distribuem em torno de uma média, com a maioria dos valores concentrados próximos a essa média e poucos valores em extremos.
Quando falamos da curva normal padrão, estamos nos referindo a uma versão específica dessa distribuição, com:
-
média \(\mu = 0\)
-
desvio padrão \(\sigma = 1\)
Essa padronização facilita a comparação entre diferentes conjuntos de dados e é a base para muitos procedimentos estatísticos, como cálculo de probabilidades, testes de hipóteses e construção de intervalos de confiança.
🧠 Por que ela é tão importante?
A curva normal padrão é usada para:
- modelar fenômenos naturais (como altura, peso, erros de medição);
- padronizar dados em escores z;
- construir tabelas de referência;
- desenvolver o raciocínio inferencial em estatística.
Curva Normal (ou Distribuição de Gauss):
Representa uma distribuição simétrica em torno da média.
Na versão padrão, a média é \(\mu = 0\) e o desvio padrão \(\sigma = 1\).
A área sob a curva corresponde à totalidade da população observada.
🎯 Medindo o Invisível
Nem sempre conseguimos observar diretamente as características de uma população. Em muitos casos, lidamos com conceitos abstratos — como inteligência, habilidade musical, produtividade ou motivação — que não podem ser medidos de forma direta e objetiva.
No entanto, mesmo sendo “invisíveis”, essas características deixam indícios nos dados: provas, testes, avaliações, questionários, desempenhos práticos. A estatística entra justamente nesse ponto: ajuda a inferir o que não vemos a partir daquilo que conseguimos medir.
- Supõe-se, por exemplo, que essas características:
- tendem a se concentrar em torno da média;
- são raras nos extremos (valores muito altos ou muito baixos);
- podem ser representadas por curvas simétricas, como a curva normal.
Estimar é medir com incerteza.
A curva normal nos oferece uma maneira de descrever essa incerteza com precisão matemática.
📐 A Curva Normal: Um Pouco Mais Fundo
A curva normal pode ser entendida como a representação gráfica de uma função matemática chamada função densidade de probabilidade.
- O eixo horizontal representa os valores medidos da variável: \(x\).
- O eixo vertical indica a altura da curva em cada ponto: \(f(x)\), ou seja, a densidade de probabilidade.
- A relação entre \(x\) e \(f(x)\) é descrita por uma fórmula:
\[
\boxed{f(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \cdot e^{-\frac{(x - \mu)^2}{2\sigma^2}}}
\]
onde:
-
\(\mu\) é a média da distribuição,
-
\(\sigma\) é o desvio padrão,
-
\(e\) é a base do logaritmo natural (aproximadamente 2,718).
Na forma padrão, temos \(\mu = 0\) e \(\sigma = 1\).
- Para cada valor de \(x\), a função retorna a altura da curva naquele ponto.
- A área sob a curva entre dois valores representa a probabilidade de que a variável aleatória assuma um valor nesse intervalo.
📈 Representação Gráfica da Curva Normal
Curva Normal Padrão:
A curva é centrada em \(\mu = 0\) e o desvio padrão é \(\sigma = 1\).
A área sob a curva representa a distribuição da população em torno da média.
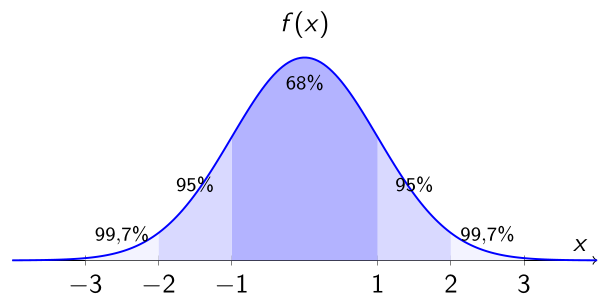
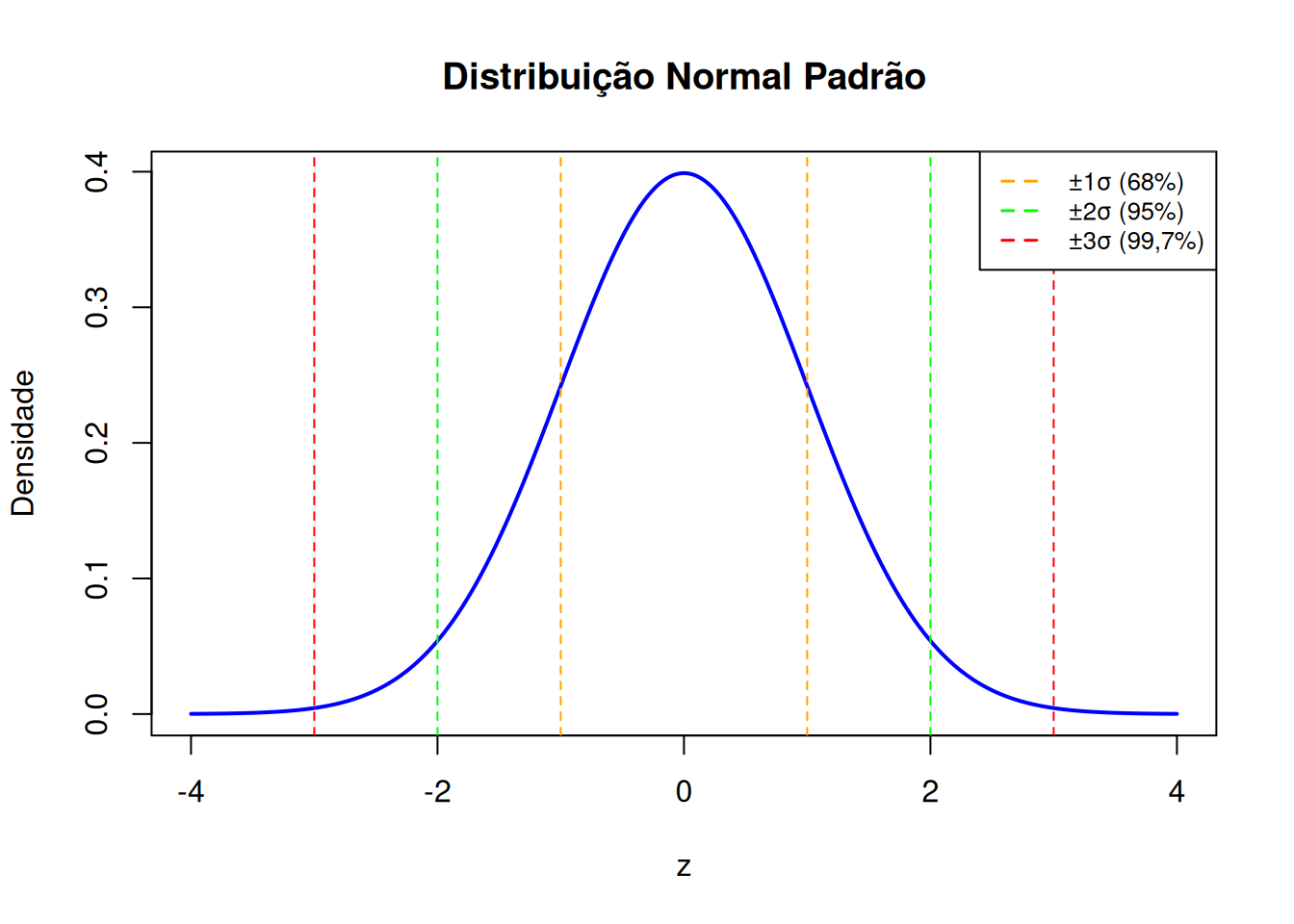
📏 Regra Empírica — 68% - 95% - 99,7%
A Regra Empírica descreve como os dados se distribuem em torno da média em uma distribuição normal padrão.
- Cerca de 68% dos dados estão entre \(\mu - 1\sigma\) e \(\mu + 1\sigma\)
- Cerca de 95% dos dados estão entre \(\mu - 2\sigma\) e \(\mu + 2\sigma\)
- Cerca de 99,7% dos dados estão entre \(\mu - 3\sigma\) e \(\mu + 3\sigma\)
A Regra Empírica é uma ferramenta visual poderosa.
Permite identificar rapidamente o que é comum e o que é raro em uma população que segue uma distribuição normal.
📌 Parâmetros da Distribuição Normal
A distribuição normal não é uma curva única, mas sim uma família de curvas.
Cada membro dessa família é completamente descrito por dois parâmetros populacionais:
Média \(\mu\):
Indica o centro da distribuição. A curva é simétrica em torno desse valor.
Desvio padrão \(\sigma\):
Mede a dispersão dos dados.
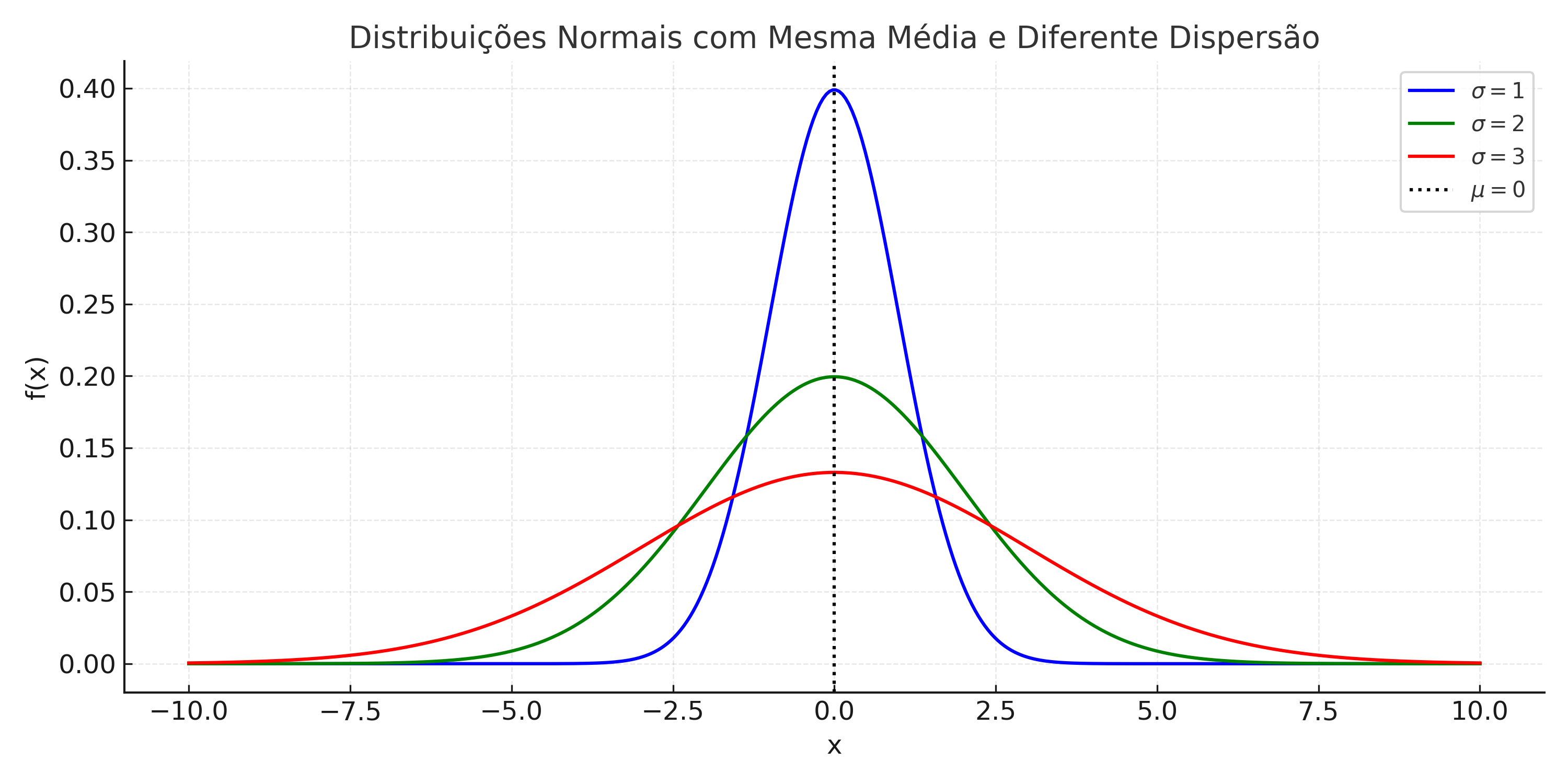
Curvas com maior \(\sigma\) são mais largas e achatadas; com menor \(\sigma\), são mais estreitas e altas.
Em qualquer distribuição normal, a curva é perfeitamente simétrica:
o lado esquerdo espelha exatamente o lado direito em relação à média.
🎯 Por que esses parâmetros são importantes?
Conhecendo \(\mu\) e \(\sigma\), podemos:
Localizar valores típicos da população;
Calcular probabilidades de ocorrerem valores em certos intervalos;
Padronizar dados de diferentes distribuições usando a transformação:
\[
\boxed{z = \frac{x - \mu}{\sigma}}
\]
Essa transformação converte qualquer valor \(x\) em um escore-z, possibilitando o uso direto da distribuição normal padrão.
Curvas Normais com a Mesma Média
A média define a posição central das curvas.
A forma (altura e largura) é controlada exclusivamente pelo desvio padrão \(\sigma\).
🎓 Exemplo: Distribuição de QI (Stanford–Binet)
Vamos aplicar a distribuição normal em um caso prático.
Suponha que os escores de QI (Quociente de Inteligência) sigam uma distribuição normal com:
- Média \(\mu = 100\)
- Desvio padrão \(\sigma = 16\)
🧠 Interpretação
Intervalo de 1 Desvio Padrão em torno da Média
A fórmula geral para calcular esse intervalo é:
\[
\mu \pm k\sigma
\]
Neste exemplo, com \(\mu = 100\), \(\sigma = 16\) e \(k = 1\):
\[
\mu - 1\sigma = 100 - 1 \times 16 = 84
\] \[
\quad \text{e} \quad
\] \[
\mu + 1\sigma = 100 + 1 \times 16 = 116
\]
Portanto, segunda a Regra Empírica cerca de 68% da população tem QI entre 84 e 116.
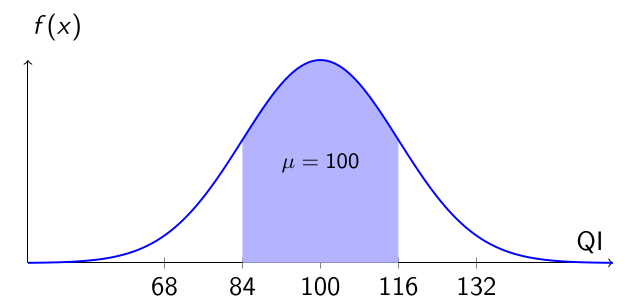
📊 Visualizando
Distribuição de QI — Intervalo de 1 Desvio Padrão
A área sombreada representa os indivíduos com QI entre 84 e 116.
Segundo a regra empírica, esse intervalo contém cerca de 68% da população.
💡 Conclusão
- O teste Stanford–Binet é calibrado para seguir essa distribuição.
- A curva normal permite avaliar o quão comum ou raro é um escore de QI.
- Escores fora do intervalo \(\mu \pm 2\sigma\) (entre 68 e 132) já são considerados atípicos.
A distribuição normal é útil para comparar indivíduos à média da população e identificar desempenhos excepcionais.
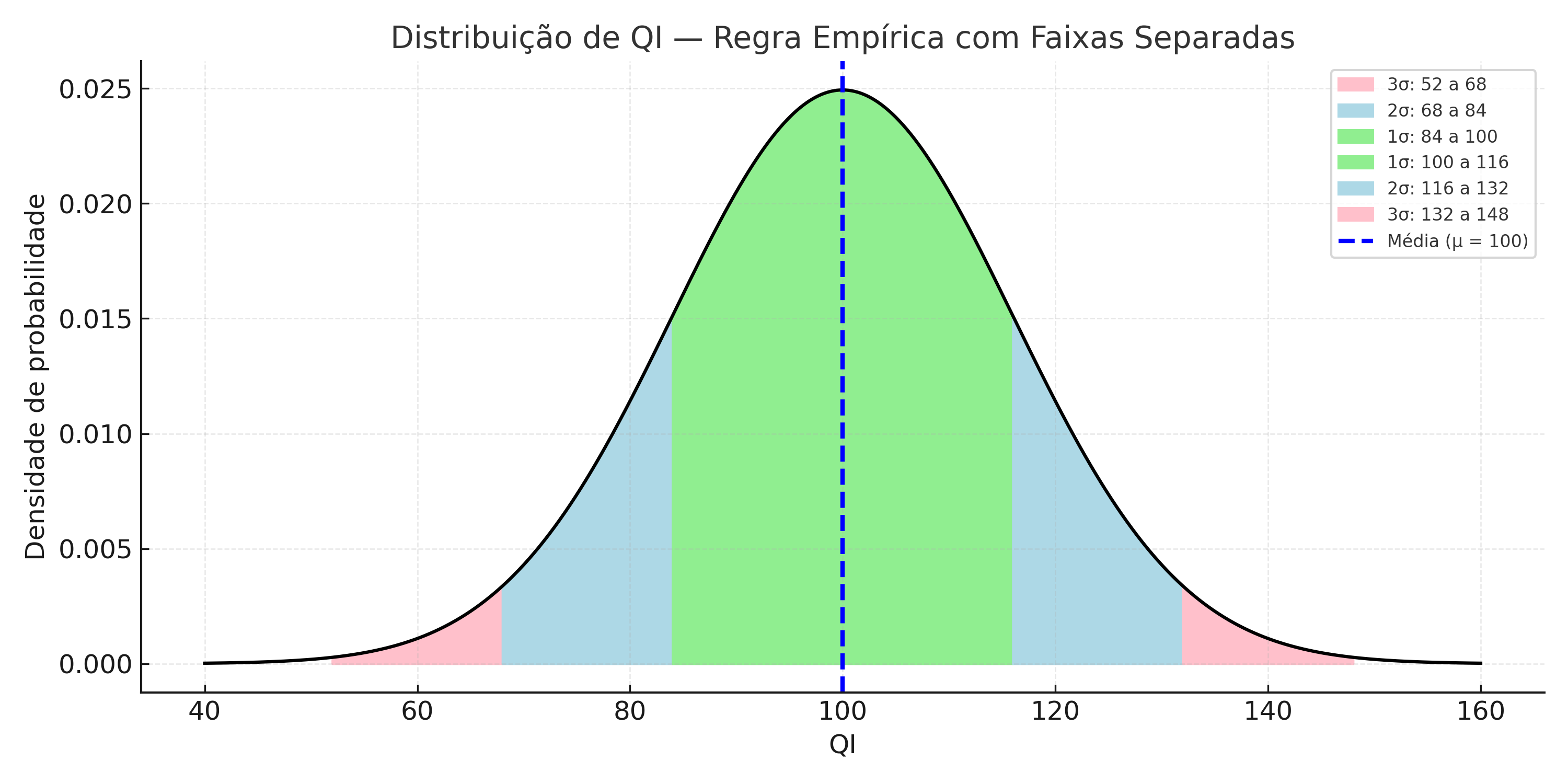
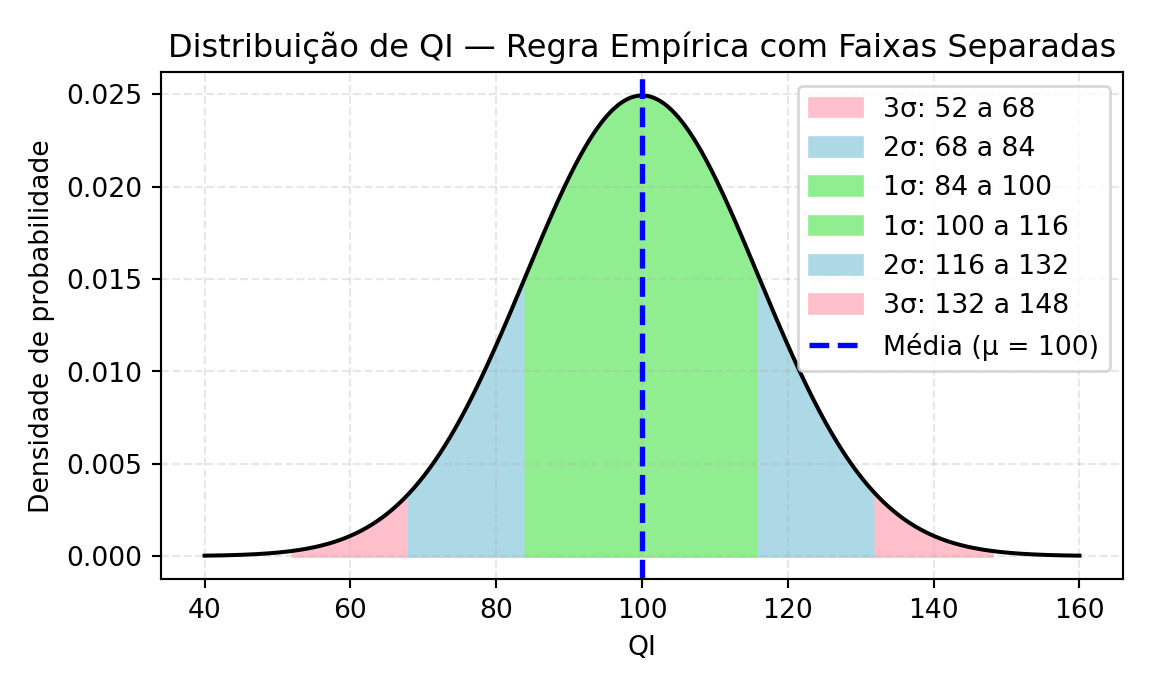
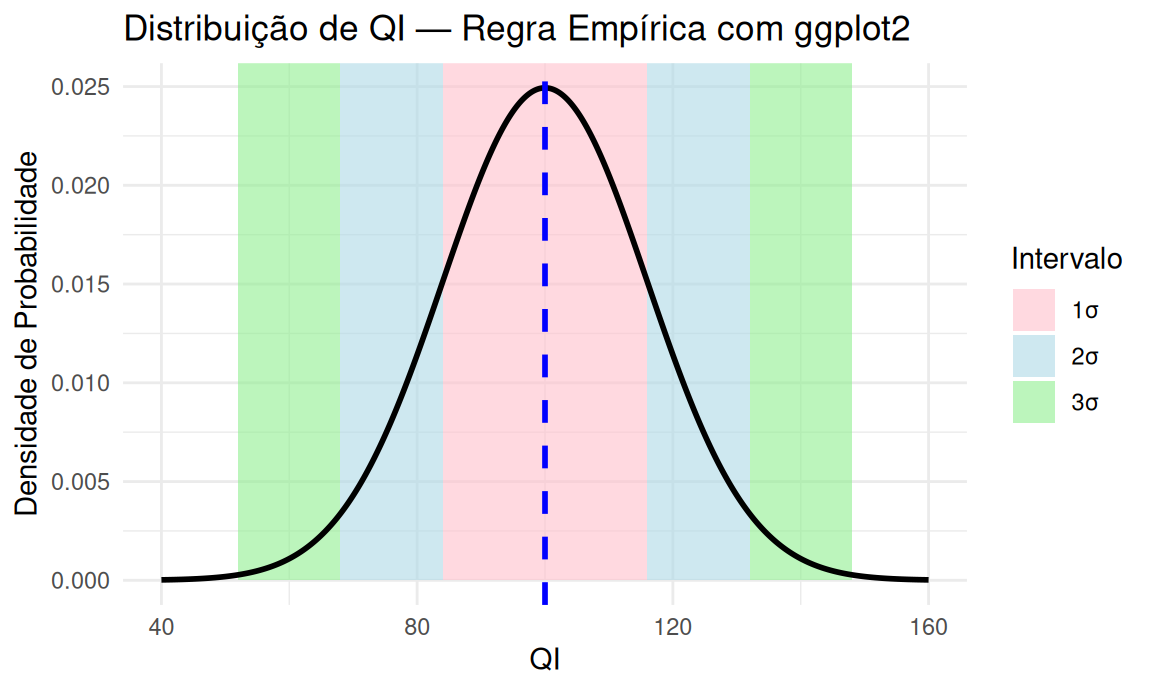
📐 Regra Empírica Aplicada à Distribuição de QI
Regra Empírica Aplicada ao QI
A distribuição de QI (com média \(\mu = 100\) e desvio padrão \(\sigma = 16\)) permite visualizar a Regra Empírica de forma clara:
-
68% dos indivíduos têm QI entre 84 e 116 \((\mu \pm 1\sigma)\)
-
95% estão entre 68 e 132 \((\mu \pm 2\sigma)\)
-
99,7% estão entre 52 e 148 \((\mu \pm 3\sigma)\)
Cada faixa da curva representa uma porção da população e foi desenhada com cores não sobrepostas para destacar suas contribuições individuais.
📐 Fundamento da Regra Empírica
A Regra Empírica baseia-se na forma simétrica da curva normal e nas áreas sob a curva, que representam probabilidades.
- A área total sob a curva normal é igual a 1 (ou 100%).
- Essa área representa a probabilidade de ocorrência de valores dentro de determinados intervalos.
- Para simplificação dos cálculos, utiliza-se a distribuição normal padrão, com média \(\mu = 0\) e desvio padrão \(\sigma = 1\).
Na distribuição normal padrão, a probabilidade de um valor estar entre dois pontos \(a\) e \(b\) é dada pela integral da função densidade entre esses limites.
🔢 Função densidade da normal padrão
\[
\boxed{f(z) = \frac{1}{\sqrt{2\pi}}\, e^{-z^2/2}}
\]
\[
\boxed{P(a < Z < b) = \int_{a}^{b} f(z)\, dz}
\]
Com base nessa função, obtemos as seguintes aproximações:
- \(P(-1 < Z < 1) \approx 68{,}27\%\)
- \(P(-2 < Z < 2) \approx 95{,}45\%\)
- \(P(-3 < Z < 3) \approx 99{,}73\%\)
Essas porcentagens dão origem à famosa Regra 68–95–99,7, usada em estatística descritiva e inferência para avaliar a dispersão de dados ao redor da média em distribuições aproximadamente normais.
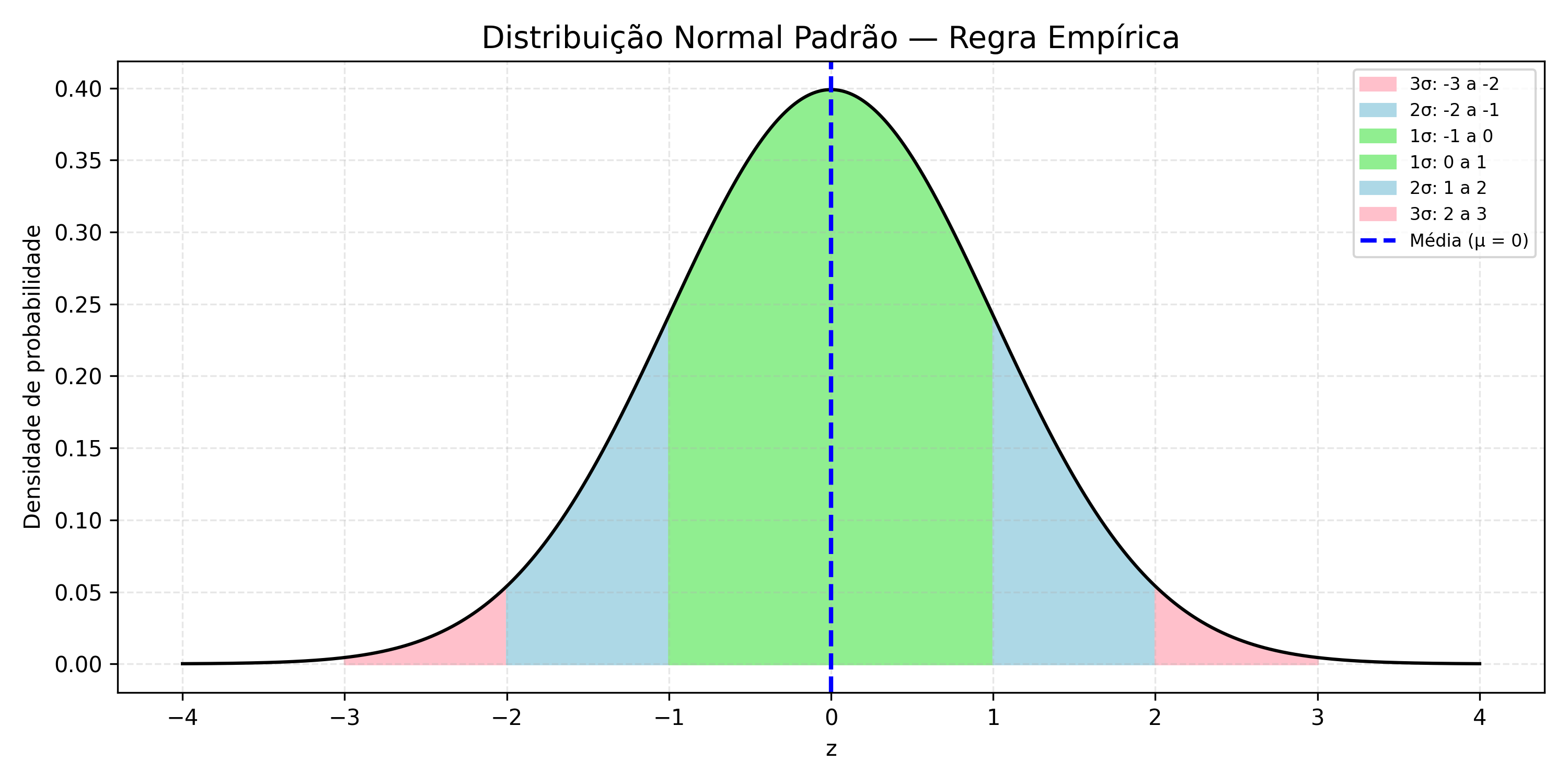
Distribuição Normal Padrão e a Regra Empírica
A imagem ilustra as faixas simétricas em torno da média \(\mu = 0\):
-
68,27% dos valores entre \(-1\) e \(+1\) desvio padrão;
-
95,45% entre \(-2\) e \(+2\);
-
99,73% entre \(-3\) e \(+3\).
A área sob a curva representa a probabilidade do valor \(Z\) estar nesse intervalo.
Funções para Distribuição Normal: Excel e R
Podemos calcular probabilidades, valores acumulados e gerar gráficos com funções específicas:
NORM.DIST(x, média, desvio_padrão, cumulativo)
→ Retorna a densidade ou a probabilidade acumulada da distribuição normal.
NORM.S.DIST(z, cumulativo)
→ Função específica para a distribuição normal padrão.
NORM.INV(probabilidade, média, desvio_padrão)
→ Retorna o valor de \(x\) associado a uma probabilidade acumulada.
NORM.S.INV(probabilidade)
→ Retorna o valor \(z\) na distribuição normal padrão.
dnorm(x, mean, sd)
→ Retorna a densidade de probabilidade em \(x\).
pnorm(x, mean, sd)
→ Retorna a probabilidade acumulada até \(x\).
qnorm(p, mean, sd)
→ Retorna o quantil \(x\) tal que \(P(X \leq x) = p\).
rnorm(n, mean, sd)
→ Gera uma amostra aleatória de tamanho \(n\).
Observação: no Excel, cumulativo = VERDADEIRO retorna a probabilidade acumulada; FALSO retorna a densidade.
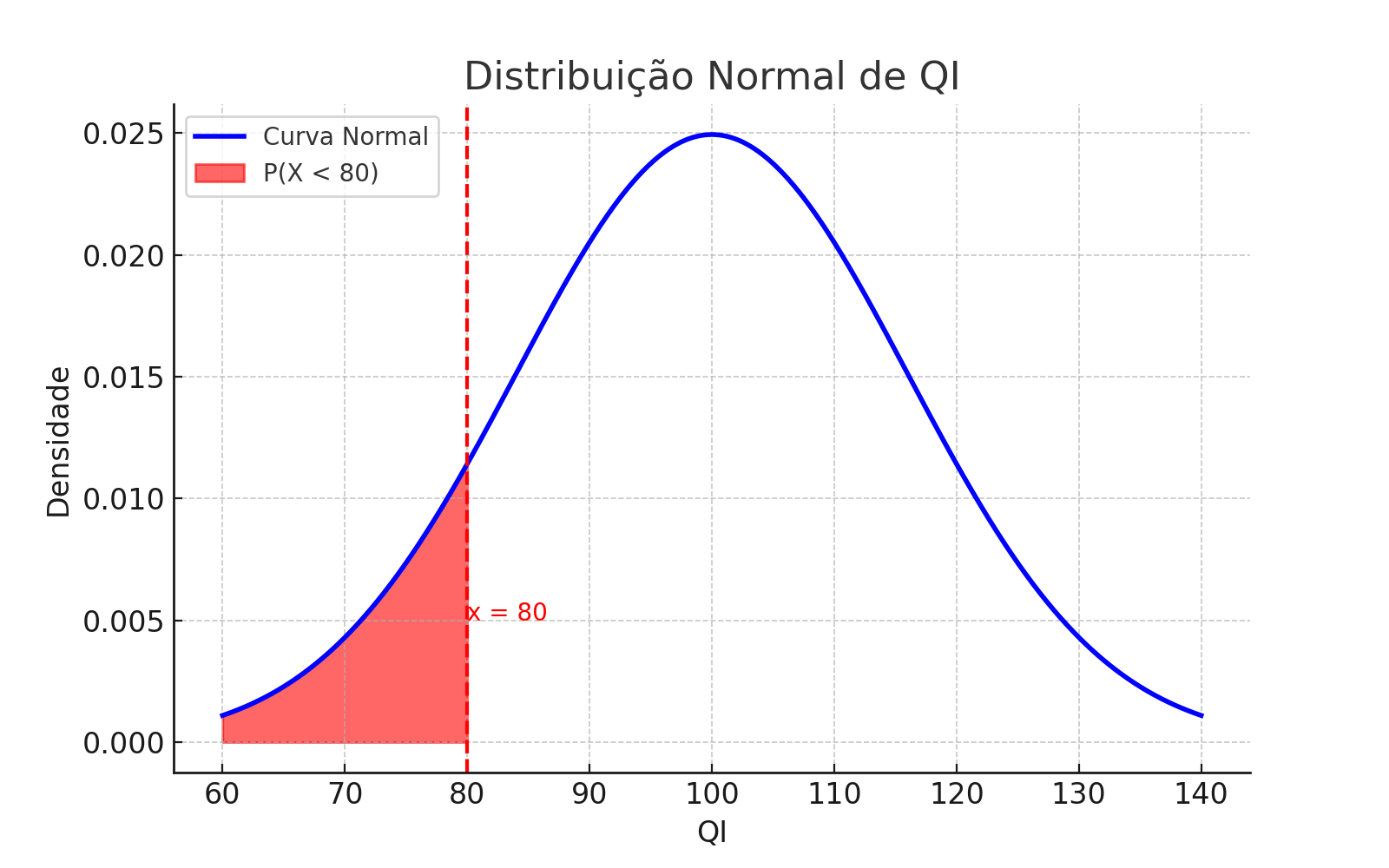
Exemplo Prático – Probabilidade de QI abaixo de 120
Problema: Qual a probabilidade de que uma pessoa tenha QI menor que 120?
Suponha que os QIs sigam uma distribuição normal com média \(\mu = 100\) e desvio padrão \(\sigma = 16\).
Queremos calcular:
\[
P(X < 120)
\]
=NORM.DIST(120; 100; 16; VERDADEIRO)
Resultado: \(\approx 0{,}8944\) ou 89,44%
pnorm(120, mean = 100, sd = 16)
Resultado: \(\approx 0.8944\) ou 89,44%
Interpretação: aproximadamente 89,44% da população possui QI abaixo de 120, de acordo com a distribuição normal assumida.
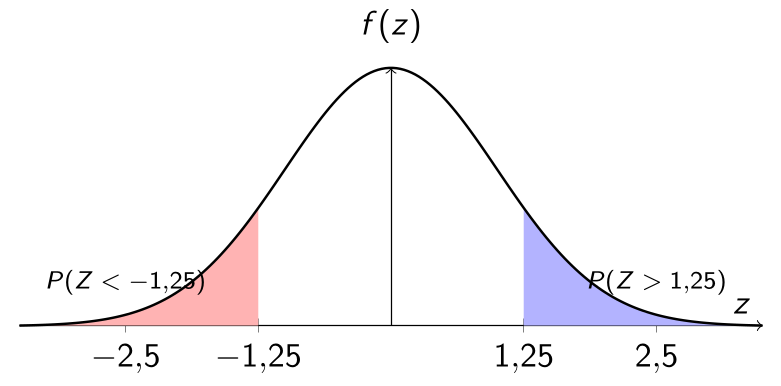
Exemplo: Resolvendo sem Excel ou R — Usando o Escore-\(z\)
Queremos calcular a probabilidade de que uma pessoa tenha QI inferior a 120, assumindo que os QIs seguem uma distribuição normal com:
- Média \(\mu = 100\)
- Desvio padrão \(\sigma = 16\)
Desejamos encontrar:
\[
P(X < 120)
\]
📖 Passo 2: Consulta à Tabela Z
Agora usamos a tabela da normal padrão \(Z \sim N(0,1)\) para encontrar \(P(Z < 1{,}25)\):
| 1.2 |
0.8849 |
0.8869 |
0.8888 |
0.8907 |
0.8925 |
0.8944 |
Tabela Z: \(P(Z < 1{,}25) = 0{,}8944\)
Cerca de 89,44% da população tem QI menor que 120, de acordo com a tabela da distribuição normal padrão.
📏 Entendendo o Escore-\(z\)
O escore-\(z\) é uma padronização que transforma qualquer valor \(x\) de uma distribuição normal \(N(\mu, \sigma^2)\) em um valor na distribuição normal padrão \(N(0, 1)\), com média 0 e desvio padrão 1.
Ele nos diz quantos desvios padrão o valor \(x\) está acima ou abaixo da média \(\mu\).
A fórmula é:
\[
\boxed{z = \frac{x - \mu}{\sigma}}
\]
🔍 Interpretação:
- Se \(z = 0\): o valor \(x\) está exatamente na média \(\mu\).
- Se \(z > 0\): o valor \(x\) está acima da média.
- Se \(z < 0\): o valor \(x\) está abaixo da média.
🎯 Por que é útil?
O escore-\(z\) unifica diferentes distribuições numa forma padrão, permitindo que possamos:
- Consultar a Tabela Z da normal padrão \(N(0,1)\);
- Calcular probabilidades acumuladas com facilidade;
- Comparar valores entre distribuições com médias e desvios diferentes.
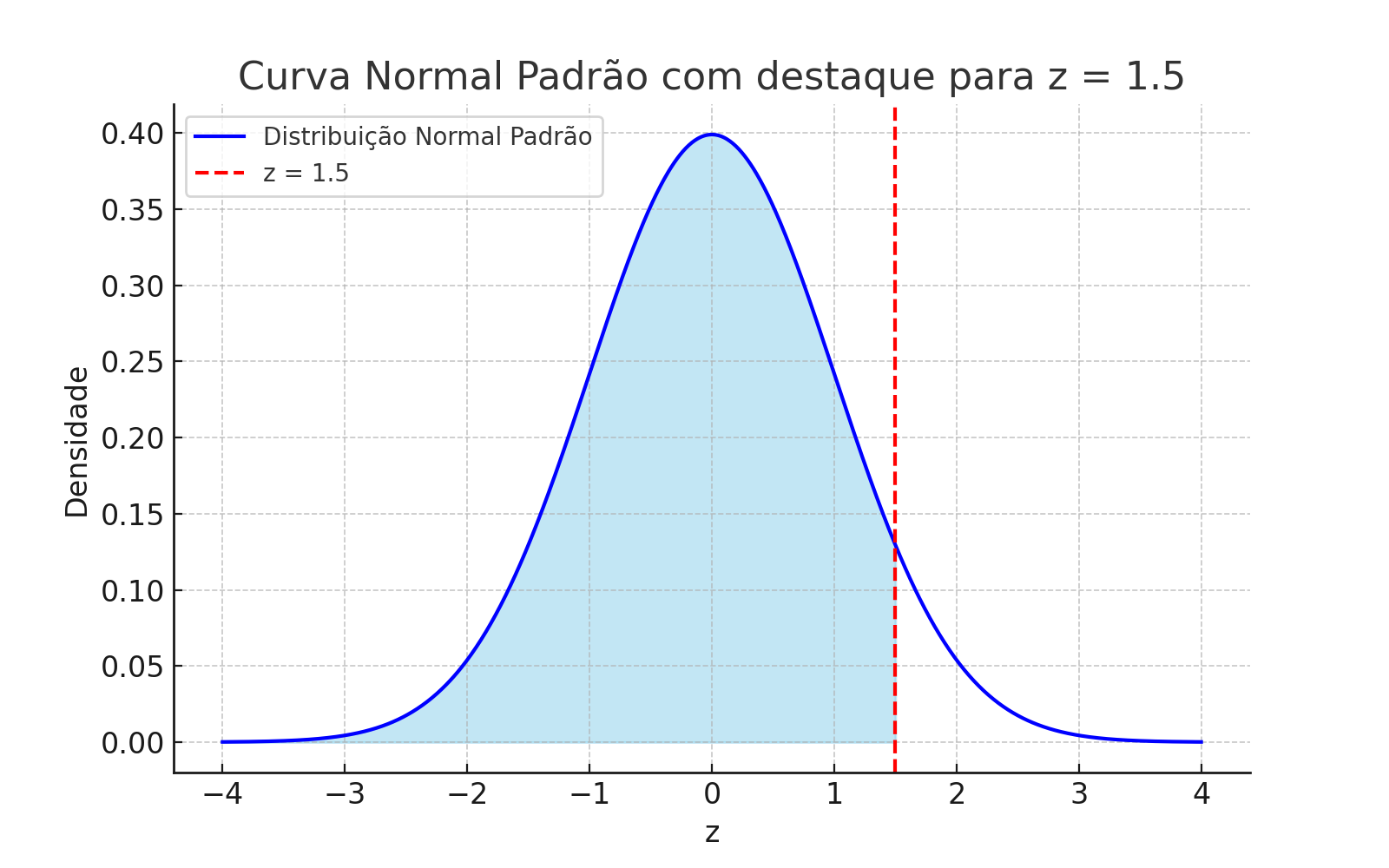
📊 Resumo Visual: Interpretando o Escore-\(z\)
Suponha que \(x = 124\), com média \(\mu = 100\) e desvio padrão \(\sigma = 16\).
O escore-\(z\) é calculado como:
\[
z = \frac{x - \mu}{\sigma} = \frac{124 - 100}{16} = 1{,}5
\]
Esse valor representa a posição relativa de \(x\) em uma distribuição normal padrão.
🔹 Área acumulada até \(z = 1{,}5\)
Aproximadamente 93,32% dos valores estão abaixo de \(x = 124\).
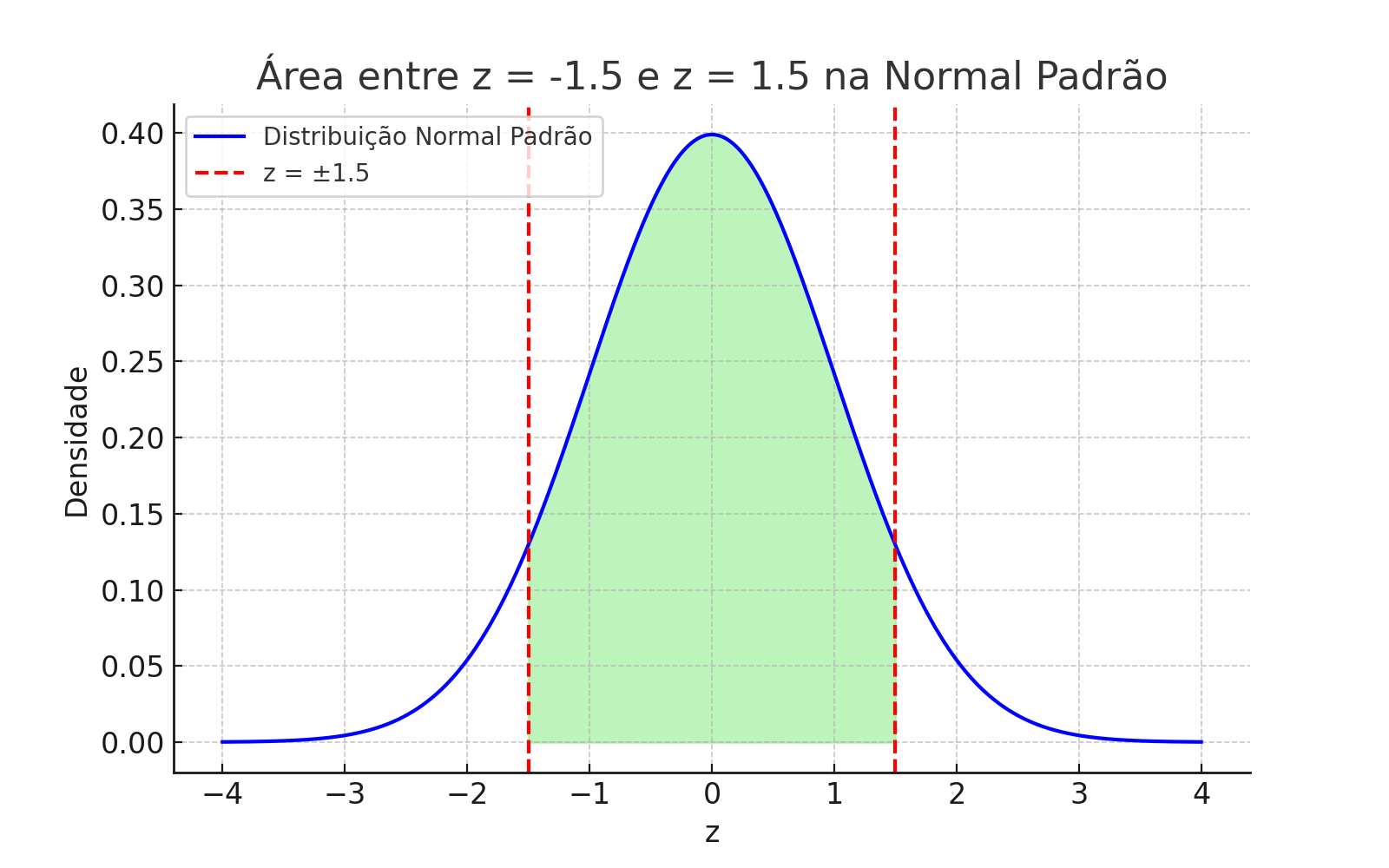
🔹 Área entre \(-1{,}5 < Z < 1{,}5\)
Aproximadamente 86,64% dos valores estão a até 1,5 desvios da média, em ambos os lados.
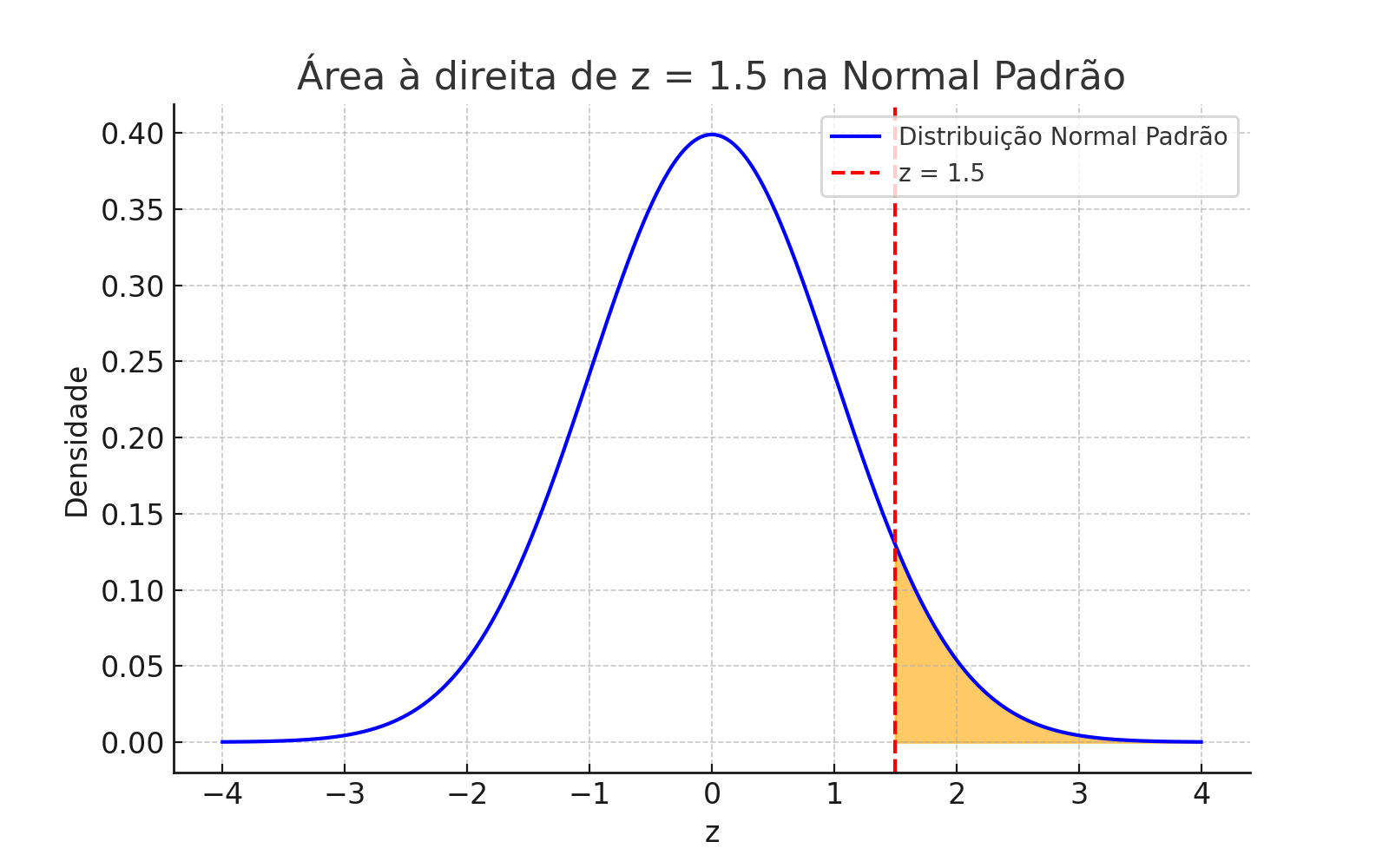
🔹 Área à direita de \(z = 1{,}5\)
Apenas 6,68% da distribuição está acima de \(x = 124\).
✅ Conclusão
O escore-\(z\) permite:
- Padronizar valores de diferentes distribuições;
- Calcular probabilidades usando a Tabela Z ou software;
- Visualizar a posição relativa de um valor em relação à média.
💡 Resumo Essencial:
\[
\boxed{z = \frac{x - \mu}{\sigma}}
\]
Essa fórmula é a ponte entre qualquer valor \(x\) de uma distribuição normal e sua posição padronizada na curva \(N(0,1)\).
🔄 Encontrando o Valor Original \(x\) a Partir de um Escore-\(z\)
Podemos também fazer o processo inverso da padronização:
- Se conhecemos:
- o escore-\(z\)
- a média \(\mu\)
- e o desvio padrão \(\sigma\)
então podemos recuperar o valor original \(x\) da variável.
🧮 Fórmula Inversa
\[
\boxed{x = \mu + z \cdot \sigma}
\]
✏️ Exemplo
Qual o valor correspondente a \(z = 1{,}5\), com \(\mu = 100\) e \(\sigma = 16\) ?
Aplicando a fórmula:
\[
x = 100 + 1{,}5 \times 16 = 124
\]
✅ Conclusão: Um escore-\(z\) de 1,5 corresponde ao valor \(x=124\) nessa distribuição.
📌 Conclusão da Parte 1: Introdução à Distribuição Normal
A Parte 1 do curso explorou os principais fundamentos da distribuição normal, incluindo:
- A curva de Gauss e a Regra Empírica;
- O conceito de escore-\(z\) e como usá-lo para calcular probabilidades;
- A interpretação da área sob a curva e suas aplicações em situações reais;
- Cálculos práticos com o uso da Tabela Z, R e Excel.
Com esse conhecimento, você já está apto a compreender fenômenos que seguem (ou se aproximam) de uma distribuição normal.